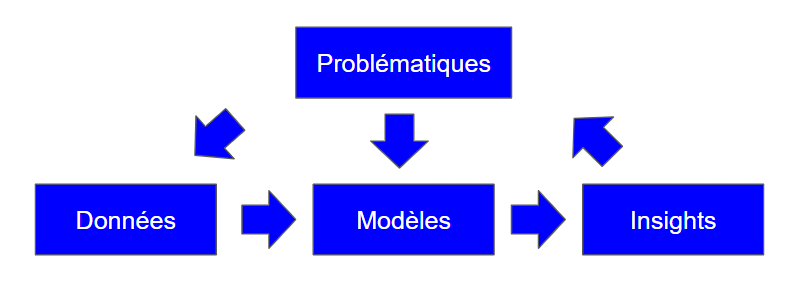
Les étapes d’un travail en IA sémantique / traitement du langage, comme dans les autres sciences & techniques des données, sont :
- La définition des problématiques (les questions que l’on se pose et où l’information manque)
- La collecte des données pertinentes pour la problématique (la réponse se trouve dans ces données, il faut les réunir pour l’extraire)
- La construction de modèles permettant d’interpréter les données
- La production par le(s) modèle(s) d’insights ou informations intelligentes (capables de répondre efficacement à la problématique et de nourrir l’action / la décision)
Les problématiques
La problématique doit être :
- raisonnée (difficile de répondre à une question immensément large ou au contraire une question hyper-spécialisée qui demanderait un travail disproportionné de modélisation),
- informée a priori (on ne se demande pas “ce que disent des données” en toute généralité, on part d’une pré-connaissance du sujet avec pour objectif de combler ce qui manque dans cette connaissance ; on sait ce que l’on ne sait pas et que l’on veut savoir),
- adossée à des données accessibles (à coût raisonnable), car les données seront la matière première de l’IA pour y trouver les réponses.
Les données
La donnée doit être :
- sous format texte dans le cas d’une IA du langage,
- de volume proportionné à la problématique et représentatif (un modèle ne fera pas de miracle : sur des données très pauvres par rapport à la diversité / complexité d’un sujet, il se trompera comme un esprit humain se trompe s’il a trop peu d’informations),
- de sources pertinentes pour la problématique (un travail sémantique concerne en général des cibles précises, ce sont les données de ces cibles dont on a besoin).
Les modèles
Il s’agit de partir de données x (x1, x2, … xn), de dimension importante, et d’interpréter ces données par une fonction f(x) dont le résultat est un certain sens de la donnée. Ici, les données sont des textes, la problématique demande une ou des fonction(s) de catégorisation de ces textes, parfois catégorisations croisées.
Les catégorisations les plus fréquentes sont :
- la détection des mots, des n-grammes, des classes de mots (lexique, syntaxe),
- l’analyse des thèmes ou topiques,
- l’analyse des sentiments ou polarité,
- la détection des entités nommées,
- la mesure de signaux forts / faibles dans les catégories étudiées.
Il est possible, et souvent utile, de construire des modèles ad hoc : détecter des aspirations, des idées, des valeurs, des identités, des quantités, etc.
L'outil Youmean vous permet de disposer de modèles automatiques, de créer vos propres modèles, de corriger et améliorer les résultats des modèles. Et les équipes Youmean peuvent construire pour vous des modèles de langage adaptés à votre secteur et à vos données.